You Do Not Need Additional Priors or Regularizers in Retinex-based Low-light Image Enhancement
TL;DR: This paper proposes a regularizer-free Retinex decomposition and synthesis network (RFR) for low-light image enhancement. It introduces a contrastive learning method and a self-knowledge distillation method to train the model without additional priors or regularizers. The approach extracts reflectance and illumination features and synthesizes them end-to-end, achieving superior performance on various datasets.

Abstract
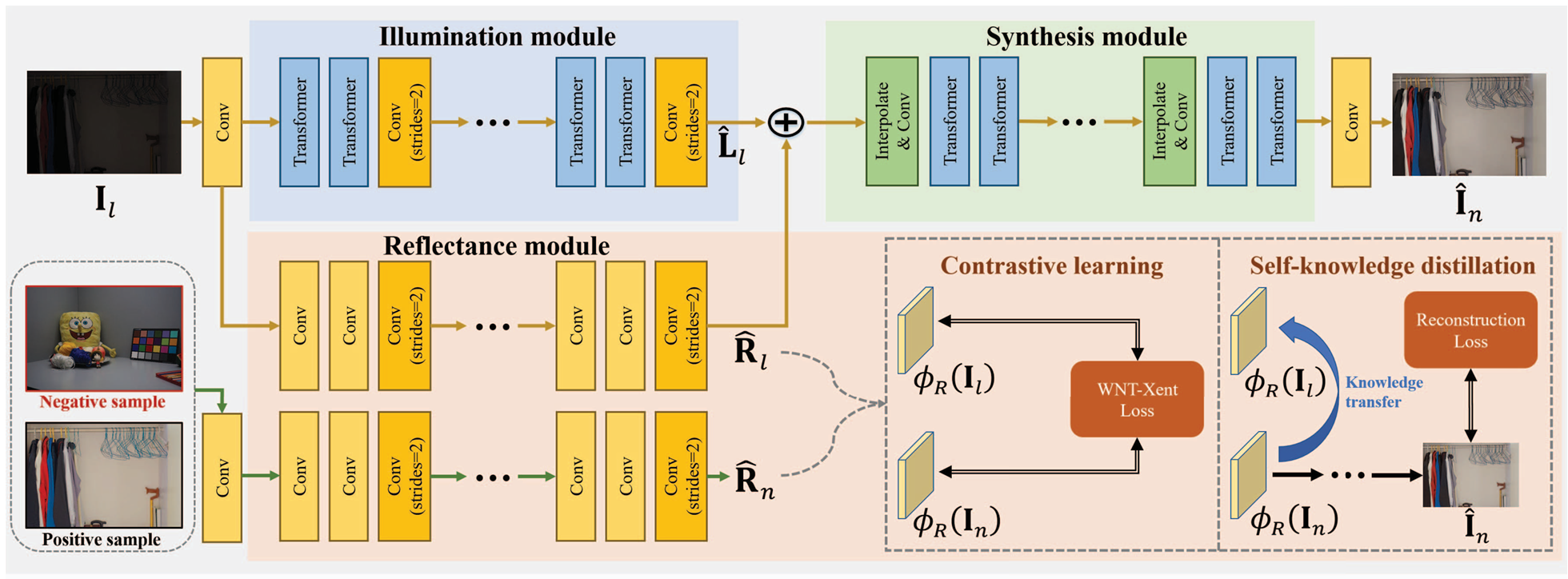
Images captured in low-light conditions often suffer from significant quality degradation. Recent works have built a large variety of deep Retinex-based networks to enhance low-light images. The Retinex-based methods require decomposing the image into reflectance and illumination components, which is a highly ill-posed problem and there is no available ground truth. Previous works addressed this problem by imposing some additional priors or regularizers. However, finding an effective prior or regularizer that can be applied in various scenes is challenging, and the performance of the model suffers from too many additional constraints. We propose a contrastive learning method and a self-knowledge distillation method for Retinex decomposition that allow training our Retinex-based model without elaborate hand-crafted regularization functions. Rather than estimating reflectance and illuminance images and representing the final images as their element-wise products as in previous works, our regularizer-free Retinex decomposition and synthesis network (RFR) extracts reflectance and illuminance features and synthesizes them end-to-end. In addition, we propose a loss function for contrastive learning and a progressive learning strategy for self-knowledge distillation. Extensive experimental results demonstrate that our proposed methods can achieve superior performance compared with state-of-the-art approaches.
Network Architecture
@inproceedings{FuYouDoNotNeedCVPR2023,
author={Fu, Huiyuan and Zheng, Wenkai and Meng, Xiangyu and Wang, Xin and Wang, Chuanming and Ma, Huadong},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={You Do Not Need Additional Priors or Regularizers in Retinex-Based Low-Light Image Enhancement},
year={2023},
}